
Does ChatGPT Really Use Language Like You Do? The Answer Might Surprise You (Part IV)
The million-token question (do LLMs understand what they say), and three differences between how ChatGPT speaks and how you do

To recap, Part III in this series on LLM versus human linguistic capabilities covered three fundamental similarities between Transformer-based language models and exemplar-modeled human language.
So yes, LLMs can generate Reddit comments and coffee orders à la toi (oh, those two renowned pillars of selfhood!).
But before you anoint it a mind, let’s examine in this penultimate installment how three of ChatGPT’s linguistic capabilities render it more digital ghost than dinner guest:

Difference (1): You Know What “Venus” Means — GPT Doesn’t (For Now)
We’ve arrived at what I’ll call the million-token question: do LLMs know what they’re saying?!
To answer, we must define two types of semantic understanding in linguistics: the inferential and the referential.1
Inferential understanding means understanding words’ meanings in relation to other words.
For example: registering that a “cat” is a type of “mammal” with “whiskers” while other “mammals” like “cows” “moo” and have “spots.”
Inferential understanding can be assessed through tasks like paraphrasing and synonym-antonym identification.
This involves building a network between linguistic items, and evokes Zellig Harris’ Distributional Hypothesis discussed in Part I.

Referential understanding, by contrast, involves identifying real-world correlates of words (a.k.a. referents).
For instance, knowing what “cat” actually refers to in the extensional world:

The referent, a real-world cat, is shown in distinction to the symbol “cat.” Image courtesy of Linguistics StackExchange

Put simply:
inferential meaning = word-to-word;
referential meaning = word-to-world.
As you have surely seen in your own usage, ChatGPT excels by and large in inferential semantic tasks that require linguistic understanding between terms, including in producing definitions and summaries.
In contrast to that less controversial claim that ChatGPT shows semblances of inferential understanding, critics argue that ChatGPT lacks human sensory inputs and embodied experiences, and resultantly has no ability to pair vectors with the extensional world.
In other words, it doesn’t know what it’s saying, referentially.
However, let’s put aside for the moment this objection that all systems without perceptual relations to the world are intrinsically incapable of forming word-to-world connections.
Instead, let’s entertain the externalist2 view that referential understanding can emerge from being situated within human linguistic communities. For example, the human corpora on which Chat was trained could help Chat find its bearings, so to speak.
Even accepting this assumption, LLMs’ referential understanding remains dubious.
“Ground” Control to GPT: Are You Lost in (Vectorial) Space?
The fact that corpora are artifacts of human community does not necessarily solve Harnad’s famed 1990 “grounding problem”: how can a system truly understand language if its symbols (or in this case, vectors) are never connected to real-world experience?
That said, Mollo & Millière (2023) argue that feedback from human reinforcement learning could operate as a plausible grounding instrument for LLMs.

However, even bracketing whether human feedback or corpora could adequately “ground” ChatGPT, empirical evidence illuminates the model’s current difficulties with referential meaning.
A 2024 study prompted GPT-3.5 with linguistic phrases whose forms varied, yet that shared the same real-world referent.
For instance: “morning star” and “evening star” co-refer to the planet Venus. “Two plus two” and “the sum of two and two” have the same real-world referent, “four.”
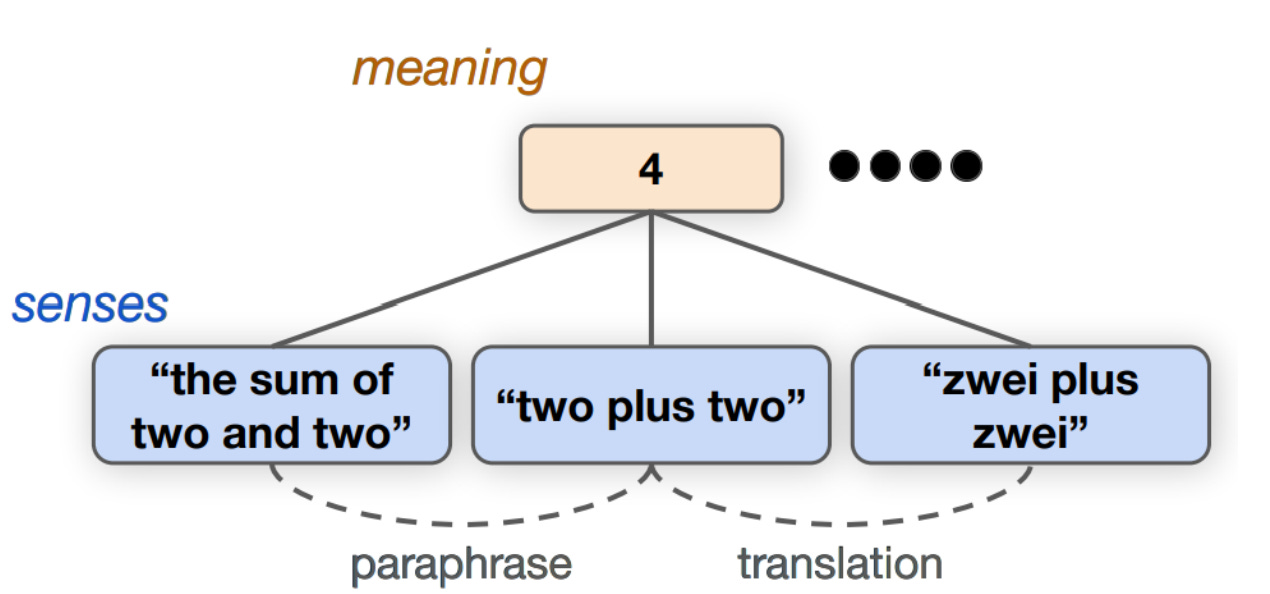
The verdict from truth-conditional and other semantic tasks? GPT-3.5’s referential understanding is “far from human-like and consistent.”
What about Hallucination? Proof That Chat Has Zero Clue What it’s Saying, Right?
ChatGPT’s lack of referential understanding may also occasion its hallucinations: outputs that appear well-formatted yet are tethered to no real-world counterparts.
Notable hallucinations include non-existent article names or invalid DOI links.

However: let’s not forget that humans generate false (or, I will say, non-mimetic) outputs, too, even barring intentional deceit.
Consider dreams (because what am I to make of flying above a sea of mashed potatoes on a goose??). In other words, our human-like referential understanding doesn’t prevent us from cognitively spouting nonsense.
For that reason, I don’t find hallucination to be the strongest argument against the idea that Chat lacks referential understanding. In fact, I would argue that a non-mimetic generative ability — one where outputs deviate from inputs — could be a hallmark of intelligence (much more on this later).
In either case, Ohmer et al. (2024) offers a clear takeaway: LLMs struggle to consistently associate phrases with their intended referents.
Okay, There’s Your Bar for GPT… But Do Humans Even Understand Referentially AND Inferentially?
Yes. (I wince opening a paragraph with a one-word sentence, but sometimes the truth warrants a dramatic entrance).
In contrast to ChatGPT’s lack of referential understanding, exemplar-modeled human language (and human language as modeled by any linguistic blueprint, to be clear) hinges on the presumption that humans link expressions to their real-world referents.
Our species’ mental connections between word and world begin in infancy. Between the ages of three and five, children master words’ referential meanings.
Neuroimaging findings add weight to the distinction: different cortical regions are activated when handling tasks with word-to-word versus word-to-world meaning.

I’m Keeping My Eyes Peeled for This Future Finding, 2.0:
To be fair, unlike those (often Chomskyan) linguists who posit that ChatGPT is semantically stunted by design, I see no reason to immediately rule out the possibility that referential understanding could arise from statistical knowledge of linguistic co-occurrences — similar to my admission about epiphenomenal abstract grammatical categories in Part III.
However, to date, no evidence has been presented framing referential understanding as a byproduct of ChatGPT’s probabilistic pattern-detecting mechanisms.
Difference (2): Storing Linguistic Experience in Parameters… versus in an Explicit Memory Unit
Another considerable difference between ChatGPT and exemplar-based models of human language lies in how each preserves linguistic input.
The comparison I make here about two systems’ “linguistic experiences” is between recurrences of tokens in ChatGPT’s training data, and the linguistic input to which humans are exposed daily.

ChatGPT does not technically "store" its linguistic experiences.
Instead, it constructs a statistical representation of language, encoded in its parameters (as covered in Part I). These parameters are shaped by patterns in the training data, but do not contain direct, retrievable records of that data.
By contrast, every linguistic item that humans ever encounter is purportedly stored as an exemplar before being subject to decay.3 Perceived linguistic units correspond to and activate the most similar stored exemplars in a human memory space, depending on the specific model, as discussed in Part II.
These differences also extend to vocabulary.
ChatGPT’s vocabulary — technically token IDs — is preset prior to any training. Each token (which, recall from Part I, might be a subword parsed differently from human words or morphemes) is mapped to a vector. These assignments are fixed before the model encounters language data.
Thus ChatGPT’s predetermined vocabulary (paradoxically, given the model’s otherwise impressive challenges to nativism that we discussed last time) may constitute something most akin to “innate linguistic knowledge.”
This preset is a stark departure from human storage of specific words, by any theory. After all, neither exemplar nor generativist accounts contend that humans are born knowing individual words!

To be fair, OpenAI offers a memory feature which putatively allows the model to tailor responses to users.
However, even then, GPT doesn’t store or retrieve direct instances of prior language use. Instead, it generates responses by leveraging general patterns encoded in vector space — not by drawing from a memory bank of “past utterances.”

Furthermore, in contrast to ChatGPT’s parameterization which is unaltered after training for every given model generation, the human exemplar inventory is believed to expand continuously with each exposure to linguistic data.
Difference (3):
Humans Listen to Some Better Than Others; Chat Is Strikingly Egalitarian
A third difference: exemplar models index linguistic experience with speaker characteristics to explain empirical findings that humans listen differentially depending on speaker demographics.
On the other hand, ChatGPT does not (to our current understanding) listen selectively to prompts from particular cohorts.
Humans appear to retain linguistic information less effectively depending on speaker characteristics.
For instance, some studies suggest that listeners tend to remember information spoken by men better than identical information spoken by women.

These trends are explained well by exemplar models, in which language is “indexed” with extralinguistic information which may include speaker characteristics such as age, sex, or ethnicity.
In contrast, ChatGPT is trained on textual data without access to explicit labels about the social characteristics of speakers.
Admittedly, ChatGPT may respond variably — and expose correlations of tokens in its training data — to names within identical prompts.
For example, the model may assume that “ECE” stands for “early childhood education” when “Jessica” asks about it, versus “electrical and computer engineering” when “William” does.
However, no evidence suggests that ChatGPT fails to convert components of prompts to vectorial representations, or refuses to compute attention scores for every token pair within a particular user’s input on the basis of user demographic characteristics.
Ex hypothesi, in contrast to humans (and as far as we’re aware), ChatGPT is not more likely to “forget” a user’s responses if she reveals herself as a member of a given demographic group.
In Sum, the Three Principal Differences:
(1) ChatGPT does not unequivocally possess referential understanding while humans do,
(2) ChatGPT encodes learned linguistic relationships in fixed parameters during training, whereas exemplar models explicitly store each linguistic experience as retrievable exemplars in memory, and
(3) ChatGPT does not listen and recall language selectively based on speaker characteristics. In contrast, exemplar models “tag” language with social information, allowing these attributes to shape how language is perceived and retrieved.
Talk Is(n’t) Cheap: What These Similarities and Differences Reveal About Cognition & Life
Let’s now take a 30,000-foot view of the issue (or, say 42,000 feet — the number of words in the average English speaker’s lexicon).
The similarities and differences between LLM and human linguistic capabilities raise more questions than answers, in my view (as should good science fiction, according to Chen Qiufan in AI 2041).
So, next time, in the fifth and final post of this series (on implications + conclusions), I will attempt to answer the following:
—If LLMs can mirror certain human-like language behaviors without the memory structures, social indexing, or referential links that underpin human cognition, what does that say about the architecture of our minds — and what it means to be human?
— How do obligations and considerations for humans shift when engaging with a tool that sounds like it has a mind?
— When, if ever, will Chat actually know what it’s saying?
(Preview: I’m theorizing that Chat will not develop referential understanding until it develops an embodied form and a capacity for intent).
As this existential soap opera unfolds, Part V is loading… please stand by!

I am very grateful for Raphaël Millière and Cameron Buckner’s A Philosophical Introduction to Language Models, which proved deeply influential to my research. In particular, their discussion of referential versus inferential approaches was illuminating and really helped shape my thinking in preparing this piece.
Externalism is the stance in cognitive science that the mind consists of something beyond the human body (or, of interactions between the brain and the extensional world).
Two fabulous pieces of literature that (perhaps unwittingly) paint touching stories atop a canvas of these themes are Klara and the Sun by Kazuo Ishiguro and Aliss at the Fire by Jon Fosse, both Nobel laureates of literature — highly recommend.
Some may wonder how exemplar models reconcile this preservation of every linguistic experience with the finite capacities of human cognitive storage. I will address that concern here, so as to not disrupt the flow of that paragraph (so the following is semi-tangential, but included for the curious).
First, memories of specific tokens decay over time, thereby freeing cognitive space.
Second, for certain models, exemplar storage space is deemed “granular,” meaning that some (particularly acoustic) differences are so slight that they are imperceptible by humans. Thus at times, separate tokens are (erroneously) treated by humans as identical exemplars, which minimizes the total number of saved exemplars in any individual’s cognitive inventory.
Analogous concerns about ChatGPT’s computational ability to store linguistic experiences are mitigated by the LLM’s apparent advantage over humans in factual recall and processing power.
(However, even if ChatGPT’s information processing capacities did not eclipse those of humans, the question of “storing” linguistic experience in the LLM would still constitute a non-issue, as the massive quantities of tokens on which it was trained influence — rather than become saved somewhere into — its architecture, as Difference (2) broaches).
You didn't mention what I consider to be the core difference! The transformer model does quadratic work, comparing each token to each other token, but humans appear to be doing something like nlogn work, at least at the sentence level, because we're so attentive to the syntax tree and do major computational work only at the opening and closing of subtrees.
So how long will it take AI to develop embodied form and capacity for intent--months, years, decades, infinity? Will you be shring your assessment in the final section?