
Does ChatGPT Really Use Language Like You Do? The Answer Might Surprise You (Part II)
How we speak -- and what Oprah's vowels reveal about the theory behind it

This installment continues the discussion beginning in Part I of this five-part series on similarities and differences between LLM and human linguistic capabilities.
Last time, I laid out a broad description of what occurs behind the veil of ChatGPT’s apparent computational wizardry (in a line, “how ChatGPT speaks”).
In this post, Part II, I introduce linguistic exemplars, which I believe can help describe how humans process and produce language based on empirical findings (or, “how we speak”).
Up next in Part III, I will argue that three primary similarities are shared between ChatGPT’s linguistic capacities and those described by exemplar-based models of human language — as well as three fundamental differences in Part IV.
I “goed” there: an obligatory preamble on Chomsky
For many years, mechanisms underlying the human language faculty have remained subject to spirited, ongoing debates in linguistics.
In this piece, I am supporting a particular framework which stands in contrast to theories proposed by the famous linguist Noam Chomsky. Let me also disclaim that my analysis may ruffle a few feathers (no pun intended for the linguists reading) in the Nativist camp.
Nativism is rooted in Chomsky’s stance that humans are born with Universal Grammar (UG), the fundamental structural principles that underpin all languages.
Evidence for UG comes, in part, from the poverty of the stimulus — the observation that children’s linguistic knowledge vastly exceeds the amount of “training data” to which they are exposed. Thus, to make sense of the fluent speech that humans eventually produce, it would follow that children must be born with some (universal) linguistic priors.
One example of these priors could be phrase structure rules: for instance, that a Verb Phrase (in a head-initial language like English) must involve a Verb plus a Noun Phrase. (Or, in linguistic notation, “VP —> V + NP”).

Nativism is also tied closely to the idea of generative grammar, which can be illustrated through the non-mimetic errors that children produce in language acquisition.
If you’ve ever been around a 4-year-old who says “I goed” instead of “I went,” you understand that she is not regurgitating the words of a parent, but producing speech that complies with a set of mental grammatical rules — for instance, that past tense verb stems in English are inflected with “-ed.” (This particular error would be termed overgeneralization).
In Parts III and IV, I will discuss in greater detail how the Chomskyan hypothesis that language arises from internalized rules and structures is challenged by LLM and human data alike.
Furthermore, the exemplar models that I find so persuasive — and their emphasis on linguistic experience over structural rules and innate knowledge — do not bode well with such Chomskyan theories.
That being said, I think that all curious minds have a great deal to learn from studying Chomskyan linguistics. In fact, and to be fair, I am very sympathetic to the idea that a hybrid framework combining exemplars with some generativist ideas may ultimately best reflect linguistic reality.
Further, I remember in college feeling stunned by Chomsky’s proposal that language evolved not for the purpose of communication, but to structure thoughts. How hyper-original and counterintuitive that felt to me. A single thinker’s ability to revolutionize a field is not to be brushed aside, but rather, studied with appreciation.

About us, carbon-based chatterboxes:
What are exemplar theories?
From my own perspective, substantial evidence suggests that exemplar-based approaches accurately model many aspects of human language.
To be clear, exemplar-based models are not a singular approach to language comprehension and production, but rather, a family of approaches.
This diverse assembly of exemplar-based models is generally united by two features:
(1) what Rens Bod and David Cochran call the cognitive “storage of linguistic experiences,” and
(2) the assumed human ability to generate and interpret language through analogical generalizations built from linguistic memories.
Be more to the point! What’s an exemplar?
“Exemplars” escape precise definition, but may generally be understood as remembered tokens or instances of exposure to linguistic items.
(Recall from Part I that human-conceived tokens — e.g., morphemes, phrases, sounds, and words — typically differ from GPT “tokens” which often appear more arbitrarily-divided to the human eye).

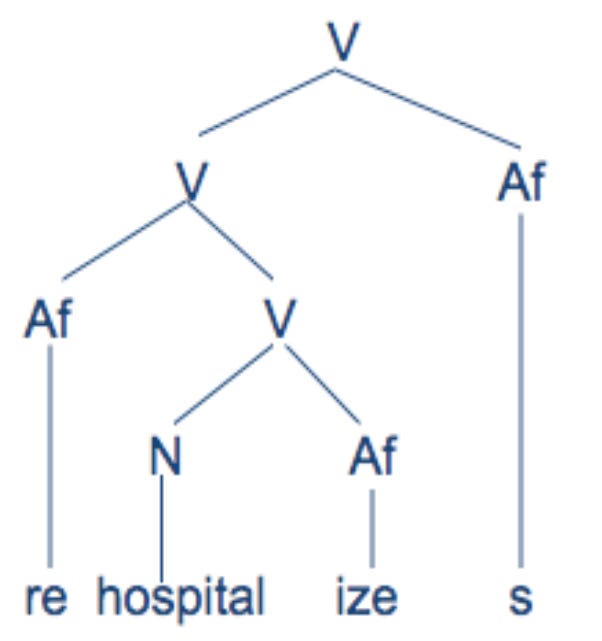
For example, an exemplar may represent an individual phoneme (a sound in a given language system — say, “s” in English), or semantic representations of described concepts.
In each case, exemplars are subsumed within constantly-evolving cognitive categories called “clouds,” which can encapsulate the range of phonetic, syntactic, semantic, and extra-linguistic information associated with each exemplar. You might think of these “clouds” as mental repositories of linguistic experiences.
Notably, the same “recalled token” — a single exemplar — may fall under more than one categorization scheme.
For instance, a memory of the phrase “supper’s ready!” could be stored in “clouds” of its constituent morphemes (e.g., the possessive “-s” inflection), and also within conceptual, socio-contextual clouds including “mom” and “female speech,” as linguist Janet Pierrehumbert explains.
If you may be so forgiving as to excuse my awful penmanship, feel free to glance at this highly informal visualization of the relationship between specific audio inputs and exemplar clouds. Each speech bubble represents a particular linguistic memory, and each cloud stands for, well, you guessed it (and we’re sticking with spoken language for simplicity):

But do exemplars actually account for how we process and produce language? 4 compelling examples
Arguably, yes. Here are 4 examples of how exemplar models surpass rule-based grammars in explanatory power:
1. Language change
Languages undergo historical shifts in both sound and meaning over time.
Consider English’s Great Vowel Shift between the 1400s and 1600s, after which the word “meat” was no longer pronounced like today’s American English “met.”
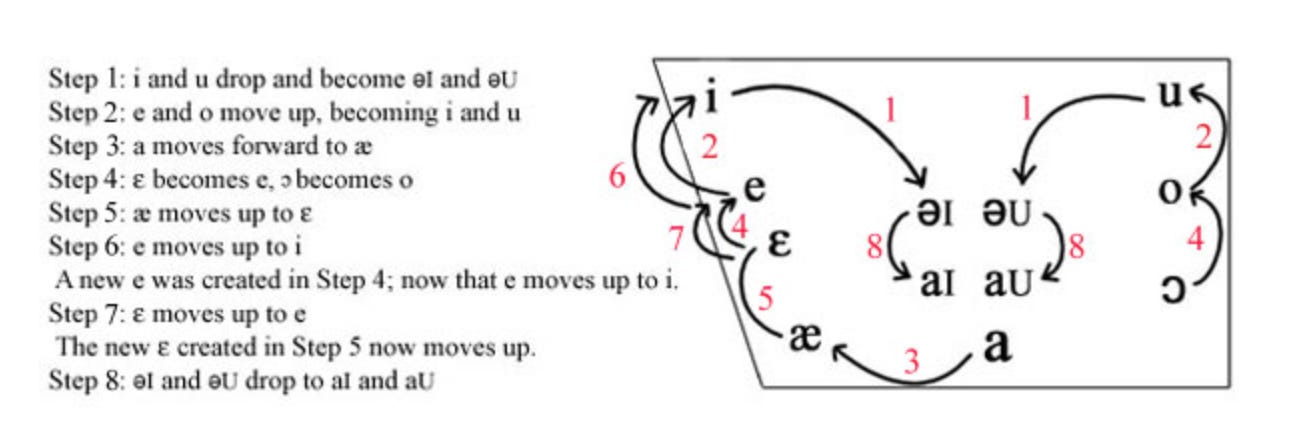
In contrast to the Chomskyan conceptualization of a “grammar” as a system of static cognitive constraints and propositions, exemplar-based models allow for ever-transforming linguistic experiences to update exemplar clouds. Recall, exemplar clouds are grounded in the idea that linguistic competence arises from exposure and usage, rather than from innate syntactic rules or abstract tree structures.
Thus the exemplar view of language as a dynamic system arguably better accommodates this reality of language change than does a rule-based grammar.
2. Frequency effects in language production
Additionally, in contrast to rule-based grammars, exemplar models of human language are supported by compelling evidence that frequency effects influence language production.
In speech, humans tend to shorten frequently occurring words, as well as words with high probabilities of occurring in a particular neighboring-word environment.
To illustrate, pronounce the following aloud (and brace yourself for the possibility that those around you question your cognitive stability and snack selections):
“peanut butter and jelly”
“peanut butter clam jelly”
(Punctuation is removed from both phrases to help control for prosodic patterns that might be cued by orthographic conventions).
Chances are, you articulated the highly probable “and” in “peanut butter and jelly” for a shorter duration than the unexpected “clam” in “peanut butter clam jelly.” (By the way, God forbid you ever be subjected to that particular triad of phonetic and culinary dissonance).
Unlike rule-based grammars, exemplar models allow for the storage and retention of detailed linguistic memories — including context-specific pronunciation behaviors, like the one shown above.

3. Frequency effects in memory
Experimental evidence indicates that knowledge of linguistic frequency not only interfaces with variations in pronunciation, but also with cognitive processes such as memory.
High-frequency words and sub-lexical units (including syllables) are retrieved (e.g., named aloud from pictures) more quickly and accurately than low-frequency ones. These findings may be taken as evidence that sub-lexical linguistic units are stored in a “syllabary.”
Again, rule-based grammars (especially when framed as a deterministic set of propositions) do not rationalize this relation between memory and usage-based knowledge of patterns in language.
4. Style shifting and such
Lastly, exemplar-based models reconcile well with style-shifting — our ability to adapt language based on social context. After all, who texts “excuse me, I’d like to interject” to one’s closest friend, and writes “lmao chill 😭” in a corporate email exchange? (Even given my generation’s admittedly documented struggles with corporate decorum, I’ve never witnessed such a word-setting mismatch in real life).
These context-dependent shifts in tone, vocabulary, and register are exactly the kind of nuances that exemplar models are positioned well to explain.
Other context-dependent speech modulation behaviors include general adjustments in accent and word-choice (code-switching) as well as changes in consonant production among bilingual speakers following exposure to their respective native languages.
Indeed, Hay et al. (1999) fascinatingly examined how Oprah’s pronunciation of the /ay/ vowel varied systematically in relation the inferred ethnicity of imagined speakers — even when those speakers were not physically present with Oprah! Exemplar theorists would champion those findings as evidence that certain extralinguistic “tags” — information about speakers and environments — are learned and stored alongside memories of particular vowels, which can later be accessed and activated for production.
On the contrary, rule-based grammars — with their formulation of linguistic constraints as cognitively universal and propositional — do not meld as well with such context-dependent shifts in language use.
We’ve now discussed some mechanisms underlying both ChatGPT’s and humans’ use of language…
But what do LLMs and machines share in common, more specifically?
How are the two different?
And are these differences of kind or of degree?
The plot thickens! In Part III, I will share three specific similarities between how GPT and humans process and produce language.
Beautifully written