
Does ChatGPT Really Use Language Like You Do? The Answer Might Surprise You (Part I)
A rundown of how LLMs work

In light of Sam Altman’s announcement earlier this month about o3 and o4-mini’s releases (and GPT-5’s delay), AI2’s recent open-source initiative to trace LLM outputs to training data, and Seoul National University’s creation of what may amount to South Korea's first medical LLM, now appears a particularly timely moment to demystify Large Language Models.
A cursory glance at Google News may suggest that LLM stands for "loudest latest mania," an apt title given the extensive media coverage — and rightfully so. The very existence of this technology poses scores of questions about the nature of communication and agency:
Do LLMs really understand language… or produce mere facsimiles of it?
Do LLM linguistic capabilities resemble those of humans?
We must consider their language processing and language production behaviors
Are LLMs “thinking” in ways that you do?
The plan (a.k.a., essay substructures come in fives)
In this series, I address the above questions through the lens of what are called exemplar-based models of human language.
How parsimonious (and relieving to subscribers) it would be if I could type a simple “yes, Chat does exactly what we do!” or a “no, it’s fundamentally different!”
But, naturally, reality is orders of magnitude more complicated than whatever would most convenience the reader and writer.
In Part I (this post), I broadly describe mechanisms underlying ChatGPT’s linguistic capacities.
In Part II, I will discuss some mechanisms underlying human language by introducing exemplar-based models, as well as compelling evidence that they do effectively model how we speak.
In Part III, I will argue that three fundamental similarities are shared between the language processing capabilities of LLMs and exemplar-based models of human language.
(Preview: evidence suggests that both we and GPT seem to use language by relying, at least to some extent, on usage-based generalizations. Empirical data on both humans and LLMs present formidable challenges to the prolific and brilliant linguist Noam Chomsky’s groundbreaking 1957 thesis that the syntax of natural languages may be represented through a system of formalized rules and constraints.)

In Part IV I will submit that three primary differences distinguish ChatGPT’s linguistic capabilities from those of humans.
(Preview: most experts don’t believe that Chat “understands” what real-world objects are… but I see no reason to think that understanding could not, in theory, be an emergent property that eventually arises from tracking statistical occurrences in what approaches the entirety of human text. Stay tuned for this take!).
Finally, in Part V I will discuss implications of these similarities and differences for artificial intelligence, cognitive science, and human life — and offer a prediction for when Chat might come to “understand” the way we do.
Is Chat all that? A note on the name
To be clear, although other LLMs deploy self-attention mechanisms, I consider ChatGPT specifically in this series not merely by way of reductive genericide, but due to the OpenAI model’s widespread usage and extensive documentation. That being said, components of the following analysis could, of course, apply to diverse transformer-based language models.
GPT’s inception
In 2018, the San Francisco-based technology laboratory OpenAI unveiled its first Generative Pre-Trained Transformer, followed by the launch of its third generation – GPT-3 – which amassed 100 million (!) active users within two months of its November 2022 public release.
(In April 2024, a college professor of mine asked our class who among us had ever used ChatGPT. Unsurprisingly, all 30 or so students immediately raised a hand. Our professor smiled, visibly impressed, and shared that he had never seen a technological innovation widely used by all of his students within a year and a half of its release. Consider, by contrast, that the internet took years — if not decades — to reach ubiquity).
As you are well aware, LLMs produce written content including cover letters, speculative historical fiction, and academic essays whose quality exceeds those of the average undergraduate student. Hailed a “technological marvel,” ChatGPT has (deservedly, in my view!) garnered appreciable attention from the scientific community and public alike.
But how does it do all of that?!
How ChatGPT Processes Seemingly Human-Like Language
GPT-4 is a neural network composed of an alleged 175 billion parameters and trained on a corpus of text data with 300 billion words. By way of comparison, British writer and broadcaster Gyles Brandreth estimated that the average person utters around 860 million words in a lifetime (yes, million with an “m”), as enshrined through one of his book titles.
Broadly, the basis of ChatGPT’s language processing and production abilities involves a Byte Pair Encoding (BPE) method, which breaks inputs into smaller units called tokens.
These tokens do not always correspond to intuitive or conventional human linguistic categories like morphemes, the smallest meaningful units in a word (for example, the “-able” in “capable”).
In fact, by the GPT-4o tokenizer (with which you can experiment yourself), “language” is segmented into one token (“language”), while “philosophy” becomes “ph,” “ilos,” and “ophy.”
Consider, indeed, how this parsing differs from the way that a native English speaker would deconstruct the words into “lang(u)” + “age,” and “philo” + “sophy,” where “lang(u)” means “relating to the tongue,” “age” is a derivational morpheme that signals a noun, and so on.

In ChatGPT, each token becomes represented as vector which, as Ben Levinstein explains well, is a “list of numbers that contains information about the word.”
This process of embedding — or converting language into numerical representations — has been fundamental to many types of Natural Language Processing (NLP) tasks for decades.
More specifically, in the case of GPT, each token is embedded into a high-dimensional vector space during its training.
Put otherwise: a 12,000+ dimension vector (which GPT uses to represent a single token) can be thought of as a unique array of 12,000+ numbers.
I will explain how Chat encodes linguistic meaning by first explaining how it does not.
Traditionally in word embedding models, semantically similar terms (such as “woman” and “girl”) are mapped near one another. Each dimension, in the conventional sense, can then be thought of as capturing a particular aspect of that token’s meaning or context:

For instance, in a classical example of semantic arithmetic which predates the development of the Transformer, Vector("king") - Vector("man") + Vector("woman") ≈ Vector("queen").

In the hyper-simplified example shown directly above: the first dimension in the vector corresponds to gender (where 0.5 is male, 0.3 is female). The second dimension corresponds to royal-ness. In theory, a third, fourth, and nth dimension could correspond to categories like squareness, whether-or-not-this-is-a-fruit-ness, belonging-in-a-spaceship-ness, and a bajillion other qualities. That would make the model somewhat interpretable, in a sense: if each vector could correspond to a real-world category.
However, that is not how Chat rolls. By its own admission, GPT’s dimensions are not “interpretable, nor are they labeled or designed with human concepts in mind. They are learned through self-supervised training, where the model adjusts these vectors so that it gets better and better at predicting the next token.”
In other words, any specific dimension of a token’s embedding in GPT does not correspond directly to gender, royalty, or any other number of human concepts. “Meaning” in GPT representations is distributed across entire vectors; no single dimension holds interpretable semantic content in isolation.
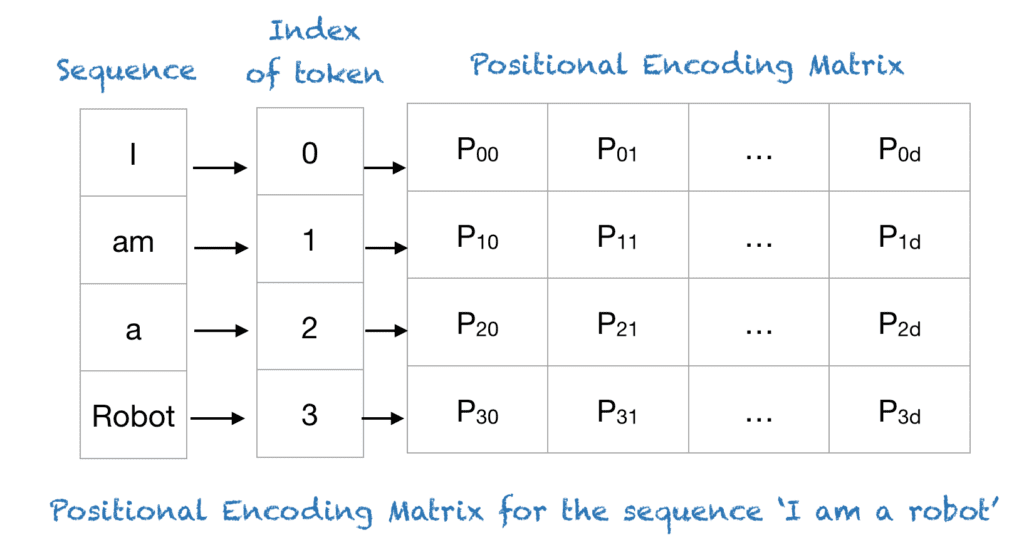
Before further processing, positional encoding is applied to these high-dimensional vectors representing each token. This step ensures that both absolute and relative information about where a token occurs in a sequence is embedded into its vector representation.
(This bottom-up probabilistic approach to language modeling is in stark contrast to Symbolic AI, or “Good Old-Fashioned Artificial Intelligence” (GOFAI), which “represents knowledge explicitly through [top-down] symbols and rules” and dominated the field of AI between the 1950s and 1970s.)

Attention, please: why are LLMs “special”?
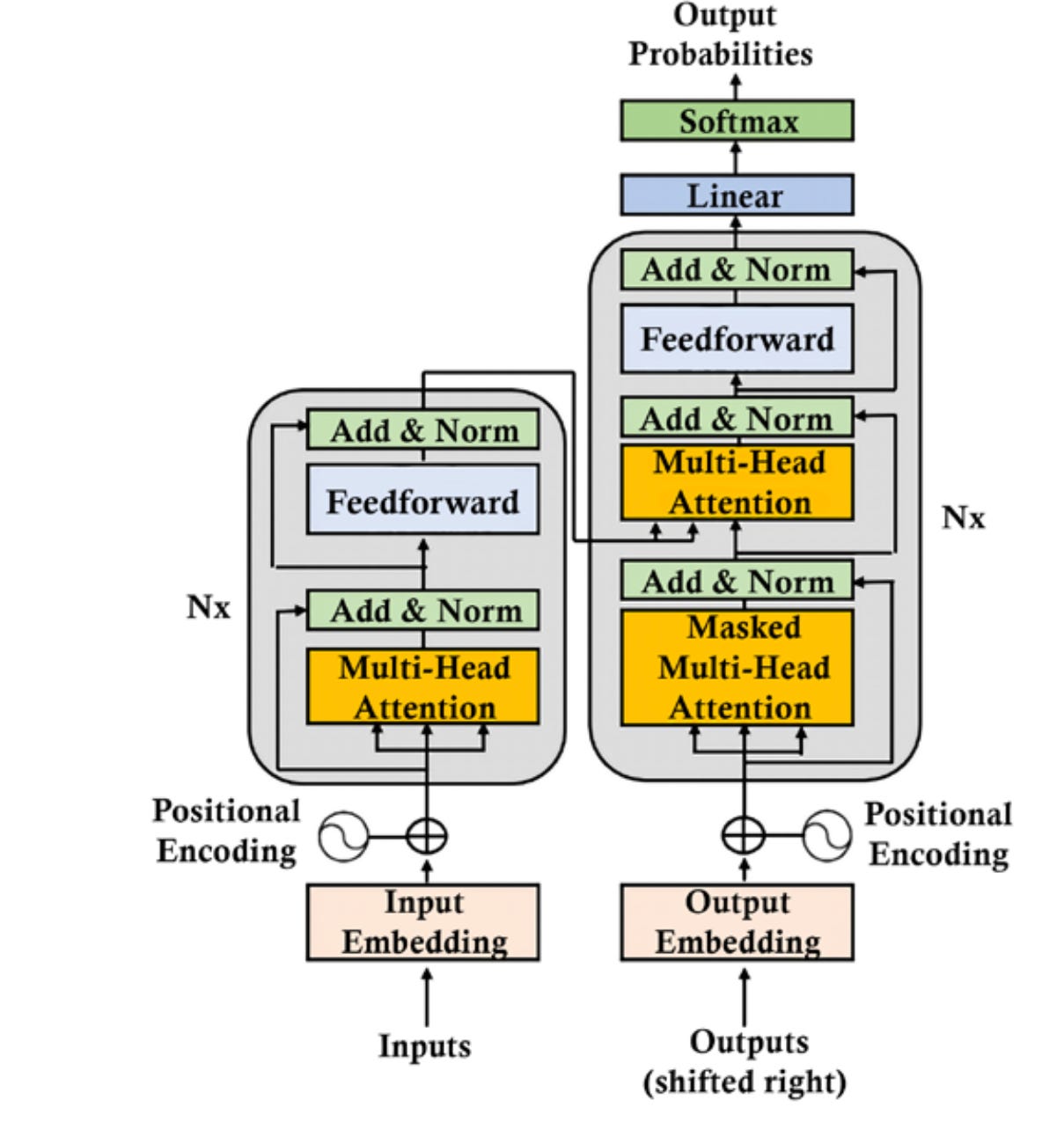
ChatGPT is then distinct from previous chatbots (such as IBM Watson and Dialogflow) by virtue of its transformer architecture.

Previously-developed language processing neural networks such as recurrent neural networks (RNNs), long short-term memory networks (LSTMs), and gated recurrent units (GRUs) process input tokens sequentially. By contrast, ChatGPT’s self-attention mechanism enables it to process all input sequences in parallel rather than serially.
This parallel processing occurs within the model's attention head, where each token's embedding (vector representation) is projected into three vectors: query (Q), key (K), and value (V). Each vector is generated by applying learned weight matrices to the token embeddings.
The dot product between a token's query vector (Q) and another token's key vector (K) yields a scalar attention score, which indicates the attention weight of one token in relation to another.
ChatGPT’s model computes this attention score between each pair of input tokens (so, “Cha” and “t” would obtain one score, “Cha” and “GPT” another, “Cha” and “‘s” another, and so on).
 in the Transformer Architecture and Why Are They Used? | Ebrahim Pichka")
In other words, after having been passed through self-attention mechanisms, the transformed vectors (which now contain information about their relation to other vectors) are passed through a feed-forward neural network called a multilayered perceptron (MLP). Glossing over technicalities, this step “transform[s] and refine the output from the self-attention layer.”
What, then, is the big picture in re attention?
Thanks to this self-attention mechanism, the model can process each input token’s relevance in relation to every other input token, which, in effect, enhances its ability to handle long-distance dependencies and other complex linguistic structures – for instance, in properly identifying the antecedent of “its” in this very sentence.
Processing, sure — but how does ChatGPT generate text?
ChatGPT and other transformer-based language models are autoregressive, meaning that they operate with the objective of next-token-prediction. As titularly suggested, this task involves predicting the most statistically likely token to follow a given sequence of tokens.
Autoregression fits within a stochastic tradition in computational language modeling, springboarding off of Zellig Harris’ 1954 Distributional Hypothesis that words’ meanings are inferred by the contexts in which they occur.
(To be honest, from my point of view, the Distributional Hypothesis’ influence in the history language technology can hardly be overstated — a bit more on that in Part III).
More specifically, using the embeddings updated by the self-attention mechanism described above, the model computes logits: raw scores for each token in its vocabulary (each token is assigned a fixed and unique token ID during training).
These logits are computed by applying a linear transformation to the contextual embeddings derived from the self-attention mechanism.

Then, these logits are passed through a softmax function, which converts logits into probabilities that represent the normalized (between 0 - 1) probability of each token being the next in the sequence that the model generates.
The model finally selects the next token based on these probability scores, appends it to the sequence, and repeats this process iteratively to produce sequences of text.
So now we understand a bit more about the technicalities of how GPT uses language… but tons of questions remain:
How do we use language?
What are specific similarities between the machine and the human w.r.t. linguistic capabilities?
Is GPT’s command of language as complex as ours?
And does it truly understand what it’s saying??
Don’t go away — we’ll broach these questions in Parts II, III, and IV!
Interesting! I need to read it again ...
This is absolutely fascinating